ALENCAR, L.
F. de . Línguas formais, gramáticas e autômatos no processamento
automático das palavras. In: ALENCAR, L. F. de; OTHERO, G. A..
(Org.). Abordagens
computacionais da teoria da gramática.
1 ed. Campinas: Mercado de Letras, 2012, p. 13-75.
Exercícios complementares sobre o capítulo 1 de
Alencar e Othero (2012)
Exercício II
(c) 2012 Leonel Figueiredo de Alencar
Questão 1: Defina os seguintes conjuntos por meio de um critério de
pertinência satisfeito por todos e apenas os membros de cada
conjunto:
a. A={Piauí, Rio Grande do Norte, Paraíba, Pernambuco}
b. B={azul, vermelho, branco}
Questão 2: Define enumerativamente o conjunto C={x | x é uma forma
simples do artigo em português contemporâneo} (consultar, por
exemplo, a Nova Gramática do Português Contemporâneo,
de C. Cunha e L. Cintra).
A Questão 3 se refere ao conhecido poema “Quadrilha”
de Carlos Drummond de Andrade:1
João amava Teresa que amava
Raimundo
que amava Maria que amava
Joaquim que amava Lili
que não amava ninguém.
João foi para os Estados
Unidos, Teresa para o convento,
Raimundo morreu de desastre,
Maria ficou para tia,
Joaquim suicidou-se e Lili
casou com J. Pinto Fernandes
que não tinha entrado na
história.
Questão 3: Construa, a partir da
gramática GD1 de (4),
uma gramática GD2 tal que um parser
baseado nessa
gramática reconheça estruturas como a de (1)
ou quaisquer outras construídas nos moldes de (2)
e (3).
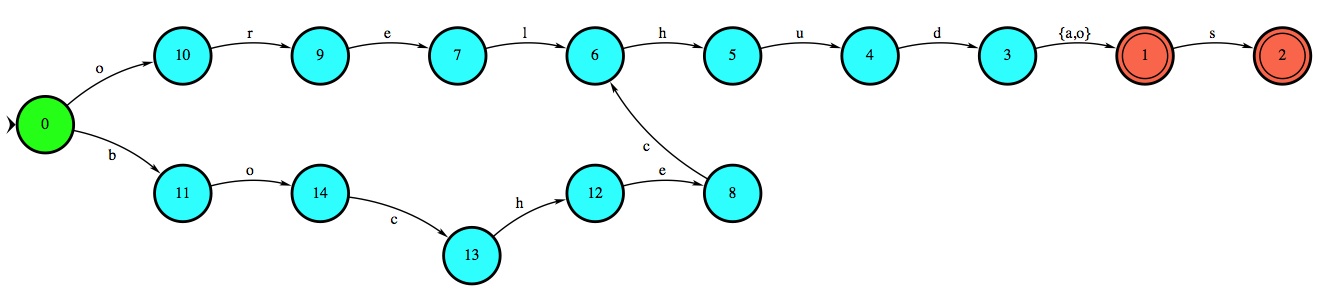
Teste a a sua proposta de gramática no NLTK por meio do Donatus.
(2) João amava Teresa que amava Raimundo que amava Maria que amava Joaquim
(3) João amava Teresa que amava Raimundo que amava Maria que amava Joaquim que amava Lili que amava Francisco que amava Joana
S → NP VP
VP → V NP
NP → N
CP → C
S
V →
{amava}
N →
{João, Teresa, Raimundo, Maria, Joaquim, Lili, Francisco, Joana}
C →
{que}
Nas seguintes questões, marque verdadeiro (V) ou falso (F) para
as alternativas.
Questão 4: Seja LD a língua gerada pela gramática GD2, proposta
como resolução da Questão 3. Sobre LD é correto afirmar:
a. Trata-se de língua infinita.
b. LD é do tipo 0.
c. LD é do tipo 1.
d. LD é do tipo 2.
a. Uma gramática do tipo 0 é capaz de gerar qualquer língua do
tipo 1.
b. Uma gramática do tipo 0 é capaz de gerar qualquer língua do
tipo 2.
c. Uma gramática do tipo 3 é capaz de gerar qualquer língua do
tipo 2.
d. Uma gramática do tipo 1 é capaz de gerar qualquer língua do
tipo 3.
Questão 6: Qual o tipo mais alto de gramática de Chomsky em que se
enquadra a gramática GD1 do exemplo (4) da Questão 3?
a. Tipo 0.
b. Tipo 1.
c. Tipo 2.
d. Tipo 3.
Questão 7: Construa uma versão GD3 de GD2 capaz de analisar os
versos abaixo do poema “Tinha uma pedra” de Drummond.2
Teste a gramática no NLTK por meio do Donatus.
(5) no meio do caminho tinha uma pedra
(6) tinha uma pedra no meio do caminho
(7) tinha uma pedra
1
ANDRADE, Carlos
Drummond de. Nova
Reunião:
19 Livros de Poesia. Volume 1. Rio de Janeiro: José Olympio, 1983,
p. 25.
2
ANDRADE, Carlos
Drummond de. Nova
Reunião:
19 Livros de Poesia. Volume 1. Rio de Janeiro: José Olympio, 1983,
p. 15.

Exercícios sobre o capítulo 1 de Alencar e Othero (2012) by Leonel F. de Alencar is licensed under a Creative Commons Attribution-NonCommercial-NoDerivs 3.0 Unported License.
Based on a work at http://teoria-da-gramatica.blogspot.com.br/2012/08/alencar-l.html.